









はじめに
どうも、カヌです。
全く関係ありませんが、第二種電気工事士を取った後認定電気工事従事者の講習を受け、つい先日認定電気工事従事者の免状が届きました!とてもうれしいです!(趣味です)
さて、前回Model Context Protocolって何者?~LLM時代の文脈管理を設計する共通言語~の記事で、MCP(Model Context Protocol)の概要を説明しました。ただ具体的な使い方などには触れていないため、今回の記事で紹介していきます。
世の中的にはClaude Desktopを用いてMCPを扱うという記事が多くあるように思えますが、個人的にはDify+Ollamaを使っているので趣味全開でDifyを押し出していこうと思います!
MCP:Model Context Protocol
前回の記事の要点を整理すると、従来(MCPが出てくるまで)はAPI呼び出し、ファイル読み込み、DBクエリ、会話文脈の挿入方法などは各実装に依存しておりバラバラでした。
MCPの導入により
- 情報取得の標準化 共通のフォーマット・手順で一貫性を確保できる
- 実装の分離と拡張性 実装依存の箇所を減らし、保守性が向上する
- エコシステムとの互換性向上 ツールやプラグインとの連携が容易になる
というメリットがあるという話をしました。
前回の記事では触れていませんが、MCPを使ってもLLMのコンテキストウィンドウを超える文脈は保持できないということ事も本記事で補足しておきます。MCPはコンテキストをさらに保持できるかのように思えますが、そこはLLM自体の性能の限界であるためMCPを使っても拡張は不可能です。MCPは銀の弾丸ではないのです。
MCPはあくまでも、従来までの実装を綺麗に整理できるように定義・提供されるインタフェースであるというだけの話です。極端な話をいうとLLM以外にも応用が可能です。
MCPの技術仕様
技術的な仕様を軽くまとめておきます。
| 名称 | プロトコル | 備考 |
| フォーマット | JSON | JSON RPC仕様に則っています |
| 通信方式 | 標準 IO/HTTP(SSE) |
標準IOが基本的な通信方式です。SSE(Server-Sent Events)というHTTPで通信も可能なように3rdパーティ製のプロトコル変換を掛けるProxyツールもあります。 |
お察しの通り、JSON RPCを喋ることができればLLMでなくとも操作が可能です。つまり一般的なデスクトップアプリであってもウェブアプリであってもMCPサーバーにJSON RPCで命令を送りレスポンスを受け取ればよいだけですからね。
デスクトップアプリからJSON RPCで命令を送り、Web上のサイトをMarkdownで受け取り、好きなサービスにMarkdownを転送してナレッジベースを作るなんてことも可能です!(ただし、データのMarkdown化はMarkdown化をサポートしているMCP Serverに限ります)
少し論点がズレましたが、今回はDifyとDifyのプラグインであるCall MCP Tool、MCP ProxyサーバーとMCP Fetch Serverを使って実装していきます。
今回やること(やりたいこと)
MCPを使って今回やってみようと思っていることですが、ブログ記事を要約してくれるAIエージェントを構築してみようと思います。ブログ記事の内容を取得してくる部分でMCPサーバーを使ってみて、使い勝手を検証していきたいと思います。
環境構築の方向性
読者が手元で試せるように、Windows(クライアントPC)で組む方針で行きます。
OSはWindows 11上でWSL2を有効にし、その中でDocker(Community Edition)を動かしています。
※業務利用する場合はDocker EEまたはDocker Desktopの商用ライセンスを使いましょう。
| ソフト ウェア |
概要 | 用途 |
| Ollama | LLM実行環境 | Difyでモデル実行するときに利用される実行環境です。GPUの利用が必須です。GPUがない場合はOpenAIのAPIを利用するとよいでしょう。 |
| Dify | ワークフロー構築 | プラグインのMCPクライアントを入れてMCPに対応させます。 |
| MCP Fetch | MCPサーバー | 外部のHTTPサーバーと通信して、URLの先にあるリソースを取ってきてくれます。 |
| MCP Proxy | MCPプロキシサーバー | DifyのMCPクライアントがサポートしているのはMCP SSE(HTTP)のみで、MCP Fetchがサポートしているのは標準IOのみなので互換性がありません。DifyのMCPクライアントとMCP Fetchサーバー間で転送プロトコルを変換する用途で用います。 |
※今回は環境構築で楽をするためにdockerコンテナ上ですべて動くものをざっくりと選定しています(記事を書く上で説明が少なくて済むので上記のような構成にしています)。ですが、あくまでも検証用の構成であり、本番環境ではよく検討した上で導入してください。
インフラの構成
ざっくりですが、インフラの構成について図を描いてみました。

インフラの準備
まずはDifyやOllamaについては公式ドキュメントが充実しているのでそちらからインストールしてください。原則はWSL2を利用してセットアップします。
Ollamaもコンテナで動いていた方がバージョン管理をしやすいのでお勧めです(LLMによってはバージョンを固定する必要があったりします)
Difyのdocker-compose.yamlを修正する
Difyと同時に起動していてほしいので、MCPで必要なコンテナをDifyのdocker-compose.yamlの設定として書き込んでおきます。
container_nameにはmcp_proxyを設定しておきます。これは別のコンテナからhttp://mcp_proxy/という方法でアクセスしたいからです。
docker-compose.yaml
# Model Context Protocol proxy
mcp-proxy:
container_name: mcp_proxy
volumes:
- ./mcp_proxy_config.json:/config/config.json
image: ghcr.io/tbxark/mcp-proxy:latest
MCP Proxyの設定ファイルの作成
以下のファイルを、docker-compose.yamlと同じディレクトリに配置します。
baseURLのホスト名は、docker-compose.yamlで設定したcontainer_nameと同じ名称に設定します。
mcp_proxy_config.json
{
"server": {
"baseURL": "http://mcp_proxy:8000",
"addr": "0.0.0.0:8000",
"name": "MCP Proxy",
"version": "1.0.0"
},
"clients": {
"fetch": {
"type": "stdio",
"config": {
"command": "uvx",
"env": {},
"args": [
"mcp-server-fetch"
]
}
}
}
}
Difyの準備
ここまで来たら、もう終わりといっても過言ではありません。
Difyを公式の手順通りにセットアップを済ませ、上記のセットアップも同様に終わらせたら、ワークフローを作ります。
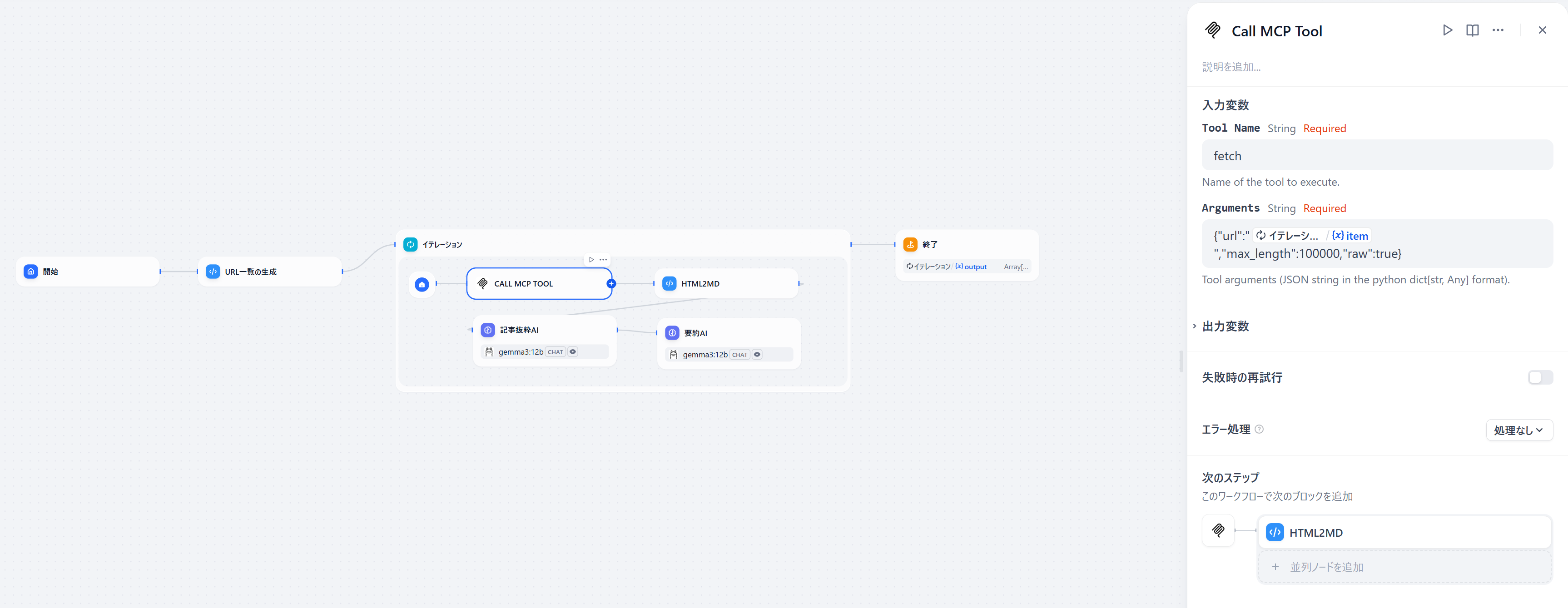
ワークフローの概要
- PythonのコードでURLの一覧を生成するとします。何らかの方法でここは事前に収集します。LLMにやらせてもいいですし従来通りのんびりクローリングしてもよいです
- イテレーションブロックで、Pythonで生成したURL一覧をクロールさせて記事を抜粋し、さらに要約します
MCPで読み込むURLは昨年書いた、クロスサイトスクリプティング【Cross-Site Scripting:XSS】でできることを読み込ませて要約させたいと思います。
実際のワークフロー
- ワークフローを作ります

- MCPに適切なパラメータを設定します(使用するサーバーのマニュアル(今回はFetchServer)はこちら)今回設定したパラメータは以下の通りです。
{"url":<<イテレーションアイテム>>,"max_length":100000,"raw":true}<<イテレーションアイテム>>は、イテレーション単位で代入される変数(今回はURL)のことを指しています。
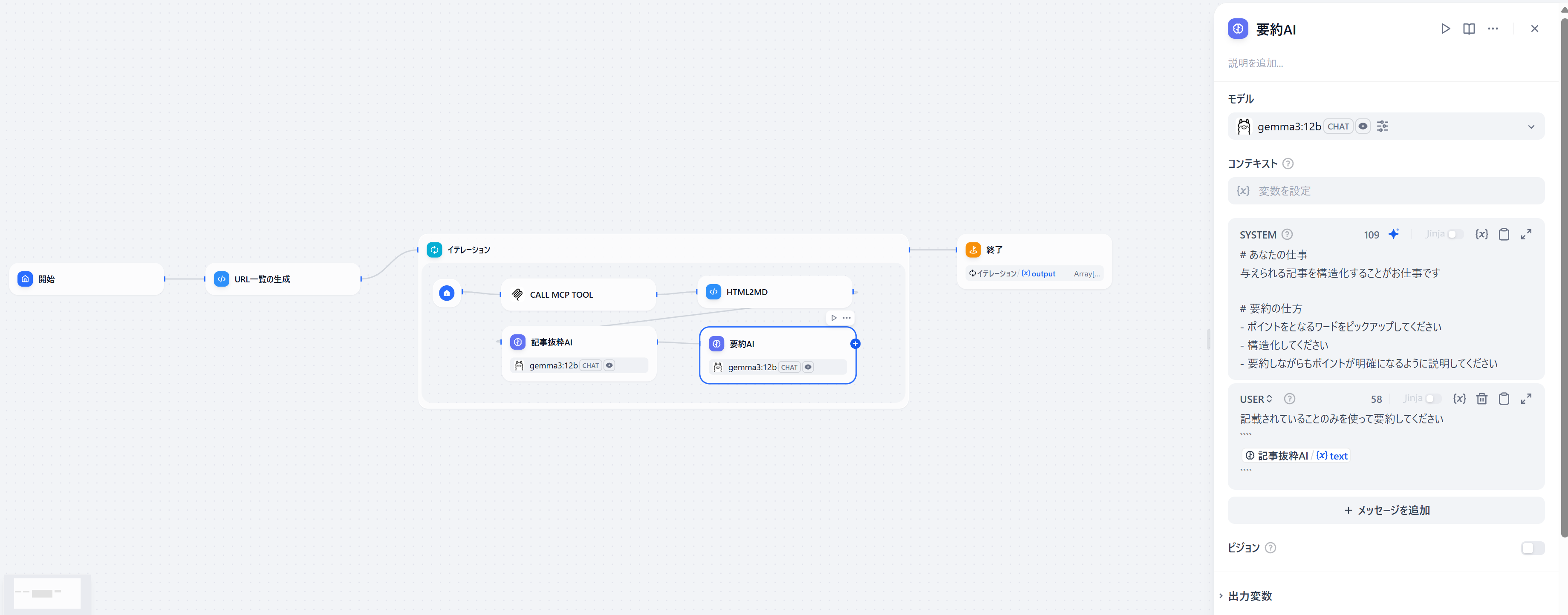
- LLMに要約の方向性を示すプロンプトを設定していきます

- 要約されMarkdown形式で構造化されています

- 実際にVSCodeで開いてみました

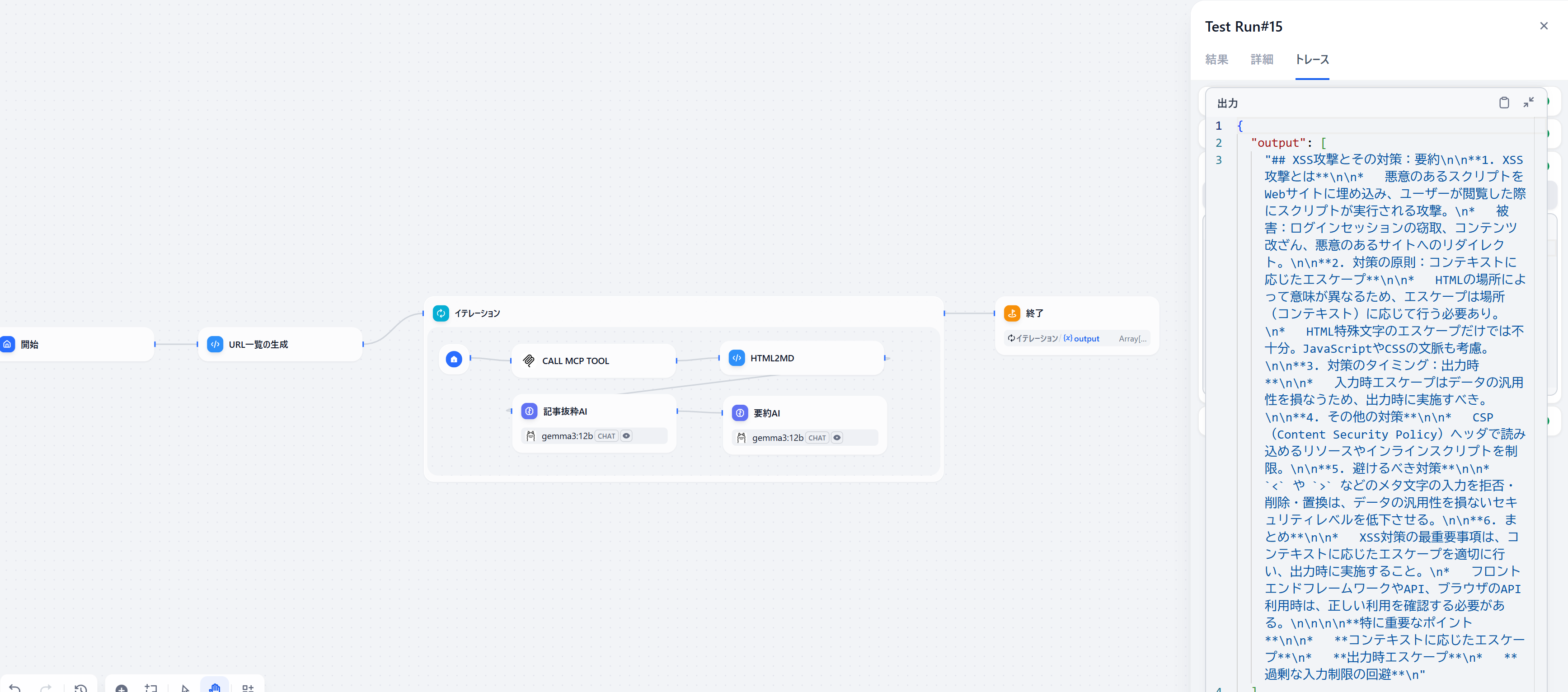
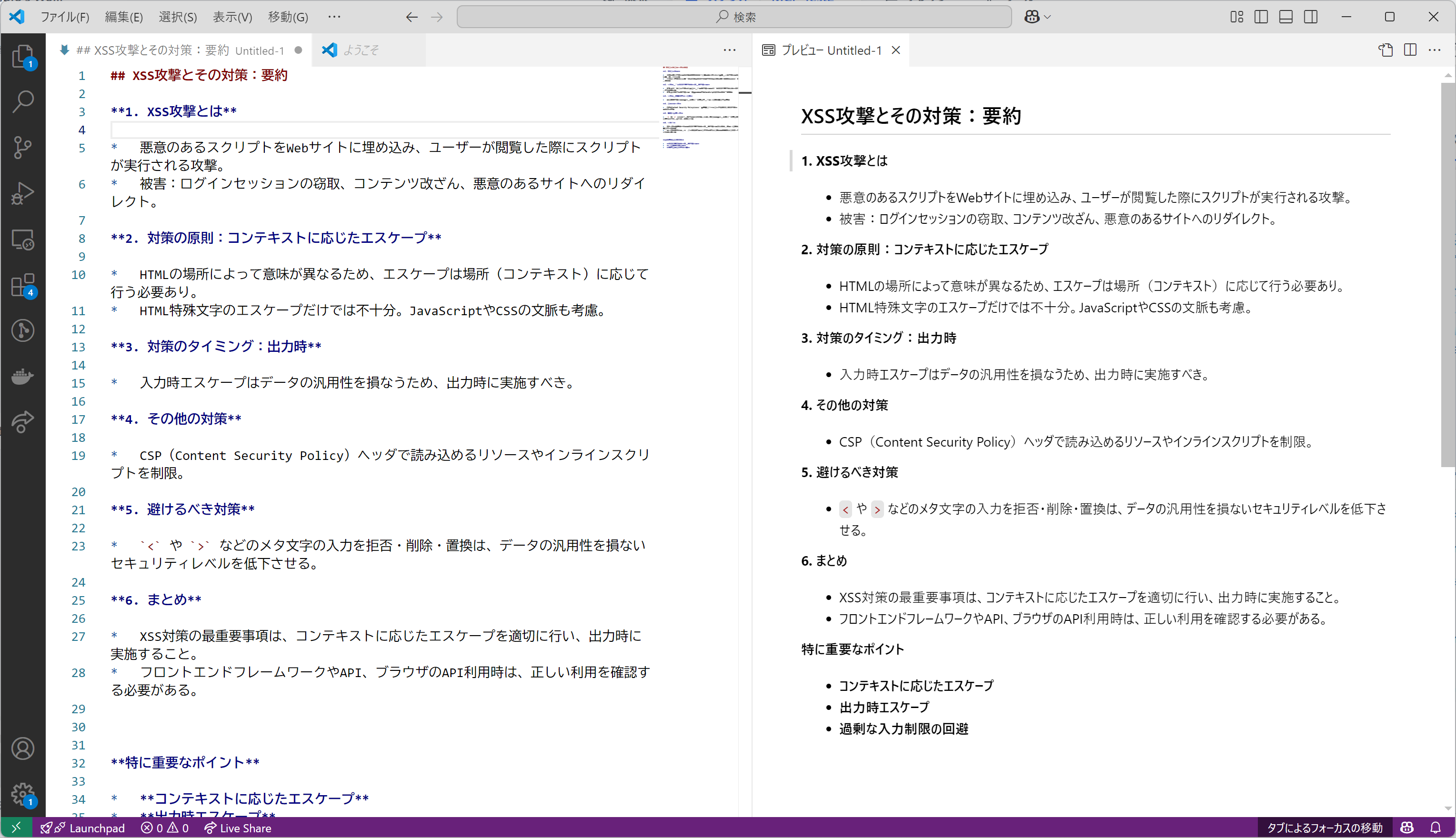
このようにLLMで記事を要約出来たらMCP+LLMを用いた記事要約Botの完成です!MCPを使うことで、Pythonなどのプログラミング言語でHTTPを直接使わずとも実装ができることが分かるかと思います。シンプルなHTTPリクエストであればDifyには元々HTTPリクエストを行う機能はありますが、Fetch Serverを別のMCPサーバに置き換えてSlackなどのチャットツールに対する自律的な操作やNotionなどのドキュメントの内容をLLMに渡して処理させるなど、この構成から大きく乖離せずに実装できることは想像に難くないでしょう。
MCPとセキュリティ
MCPというプロトコルを利用するために、今回は様々なツールを組み合わせました。特に今回はMCPを実装したMCP Fetchというツールがもし悪意のある実装者であった場合に以下のような攻撃手法が考えられます。
※あくまでも一例であり、攻撃手法のすべてを列挙したわけではありません。
想定されるセキュリティリスクの例
- 間接的なプロンプトインジェクション
ツール自身がHTTPレスポンスなどに不正な指示(プロンプト)を混入したり、ウェブページそのものに悪性プロンプトが存在する場合にプロンプトインジェクションが発生します。 - ツールポイズニング
ツールの説明文に悪意あるプロンプトを忍ばせてその呼び出しを通じて被害を与える攻撃です。プロンプトインジェクションの手法の一種です。
間接的なプロンプトインジェクションについて
LLMが解釈した結果を直接利用してメールを送信したり、ファイルの読み取りをできるような仕組みである場合には不正な送信先・文章を追加されたり不正なディレクトリからのファイル読み込みや書き込み等の攻撃による被害を受けるリスクがあります。
MCPサーバーを使うにあたって発生する例を挙げるとすると以下が思い浮かびます。
- MCPサーバーが悪意のある物だったとしたときに、LLM側に渡すデータにMCPサーバーが悪性のプロンプトを紛れ込ませるパターン
- MCPサーバーが読み込む対象のデータ自体に悪性のプロンプトがあるパターン
ツールポイズニング攻撃について
間接的なプロンプトインジェクションの一種に、ツールポイズニング攻撃という攻撃手法が存在します。この方法はMCPツールの説明文に悪意のあるプロンプトを埋め込み、その説明文をLLMが解釈し解釈結果をそのままオーケストレータが実行することによって発生する攻撃です。最初に説明文を確認して問題がないとなったとしても、インストール後に内容を確認せずにアップデートされる環境である場合ツールポイズニング攻撃を受けてしまう可能性があります。
今回作成したワークフローについて
今回構築したワークフローでは「本文抽出LLM」が悪性プロンプトを実行するターゲットとなり得ます。
今回のワークフローでは機密情報に触れるようなフローを組んでいるわけでも、メールを送るようなロジックを組んでもいないため実害はほぼありません。
LLMにデータを渡して解釈させる以上、必ずプロンプトインジェクションのリスクが存在します。
どのようなデータが、どの経路を通じてLLMに渡されどのように処理されるのかを常に考慮する必要があります。
今回のワークフローにおいて懸念点があるとするならば、MCP Proxyの設定ファイルに"addr":"0.0.0.0:8000"という記述をしていますが、すべてのインタフェースでネットワーク接続を許可してしまっていることでしょうか。
このあたりも、次回の記事にて説明できればと思います。
感想
WebサイトアクセスのためのHTTP、DBアクセスのためのSQL、ファイルにアクセスするためのファイル読み込みAPIを叩くコードなど……。実際にデータを読み込むとなれば、それなりに実装のコストがかかるインタフェース実装をJSON RPCを標準IOもしくはHTTP(SSE)経由で発行すれば済むようにラッピングしてくれるという所が「AIのUSB-C」というように比喩される由縁ですね!使ってみたところ、かなり使い勝手が良い物(導入もコマンド一発で楽)なので応用範囲は広そうです!
MCPサーバーにはPuppeteerの実装もあるようなのでSPAなサイトにも対応できそうですね!生成AI/LLMを使う開発技法はしっかり追っていきたいものです!
まとめ
- MCPという技術は、外部リソースへのアクセスを容易にするためのラッパプロトコルです。
- 通信する方法としてSSEも選択できます。
- セキュリティ面では、LLMの特性とツールの実装方法に起因するリスクを正しく理解し、前提条件と被害例を整理することが重要です。
次回は、今回取り上げたMCPのセキュリティについて、もう少し掘り下げてみたいと思います!



